Why am I building an LLM agent for students on my campus?
An Excess of Information
In today’s technology-enabled universities, students are bombarded with an overwhelming amount of information. At Princeton alone, the website hosts thousands of pages of text about programs, academics, opportunities, resources, and college life. I wish I had known half of this information three years earlier, but sifting through these pages is not possible for a single person who might not even know where to start.
Information is Too Highly Distributed
Information on campus is fragmented across numerous apps and websites, making it hard to stay up-to-date on a daily basis. The TigerApps ecosystem, for instance, comprises over a dozen individual apps, each serving a specific needs. Beyond these student-created apps, Princeton news, menus, campus events, and schedules are spread out across individual platforms. Students are fatigued from needing to visit so many places.
Informal Knowledge is Unindexed and Untapped
Beyond the official information channels (like the Princeton website), there exist many sources of informal knowledge — email listservs, word-of-mouth, forums, course reviews, etc. However, these knowledge channels, despite being incredibly useful, remain largely unindexed and untapped. LLMs can change that.
Students Want Answers and Support
Students need nuanced answers to their complex and often personal questions. They require support throughout their educational journey, and static information pages or limited advising appointments cannot meet these demands. Students crave real-time, personalized responses that cater to their unique situations and goals.
The Situation is Right
I was elected as the new president of TigerApps, so I have access to Princeton’s APIs, existing student apps with their data stores, connections to faculty and OIT, funding, and credibility. LLMs and agents have also reached a mature enough stage to be deployed into production, and students are generally familiar with chatbots through ChatGPT.
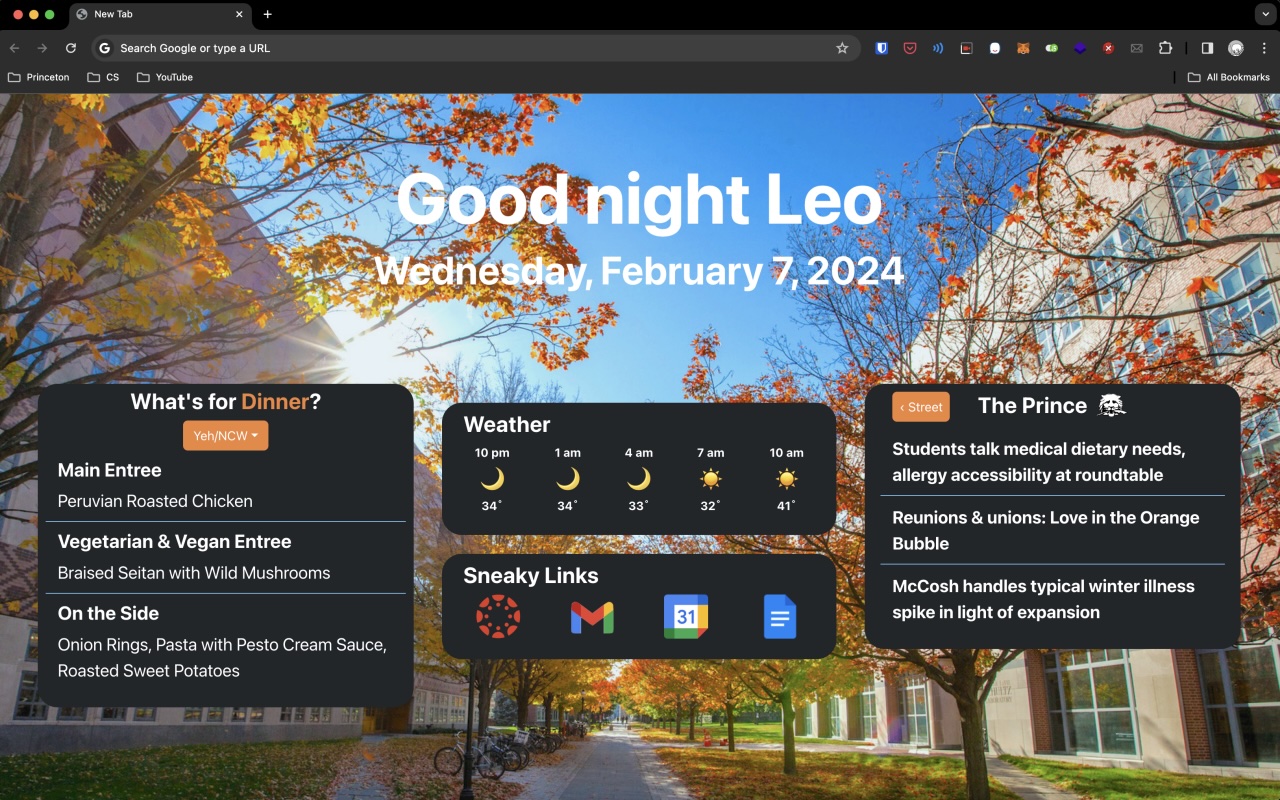
The "Today @ Princeton" browser extension.
The Journey
A year ago, I started working on making information more accessible to students by building a browser extension that replaces your new tab page with campus-related information widgets. This app quickly gained traction, reaching 450 daily users. It addressed the problem of daily information access by centralizing dispersed data into one easily accessible location.
However, I soon realized that the next logical step was to leverage LLMs. Students now seek answers to more complex questions, and personalized responses can’t be provided through a simple widget system. This lead me to dedicate the last semester to developing a chatbot with the guidance of Professor Netravali and one of his PhD students. Our focus was on answering questions based on website content on the Princeton domain. After experimenting with various retrieval strategies and configurations, we created a working demo.
Currently, I am working on transforming this chatbot into a more advanced agent capable of sourcing information directly, using tools, and performing reasoning tasks. This involves two main challenges: unifying the different data sources and ensuring the agent itself functions effectively.
Some data sources are well-indexed and have APIs, while others, such as email channels that broadcast events, require indexing. One function that I want the agent to have is to find all upcoming events that are interesting to a student and sign the user up for them. This requires creating a data ingestion system — likely also LLM-based — to process the unstructured data sources before integrating them into the main agent.
The ultimate goal would be to have the chatbot derive the informal knowledge that students have from its conversations and data sources in order to pass on to future users.