AI assistant progress / Perplexity goes after students
Two weeks ago, I launched a chatbot to help Princeton students answer any questions they have about campus. You can read the post here . Since then, there has been a lot of work done to analyze thousands of messages and find places where the system needs improvement. We’ve also begun work on a mobile app. Meanwhile, Perplexity recently launched a feature for some college users where you could select a “focus” mode and query only sources relating to your school. I’m excited to say that we’re outperforming their system on both speed and answer quality. Much of that is due to our deeper integrations with the Princeton ecosystem (ala a private search engine).
Focus mode for Princeton, accessible through the Perplexity web interface.
Conversation Analysis
The first step in analyzing user queries was to do clustering. The procedure was fairly straightforward: embed the user queries, then run K-Means clustering on the embeddings. The dataset is relatively small, so I performed the clustering on high dimensional embeddings (as opposed to having a dimensionality reduction step in between). I tried using both OpenAI text-embedding-3-large embeddings and embeddings-gte-base from Replicate (both 768-dim). One concern I had when trying OpenAI embeddings was that the dimensions might have unequal importance. When looking at their embedding API, they describe how you can truncate the embedding vector from the end while retaining most of the performance. However, K-Means assumes that all features have the same weight. In practice, I didn’t see a difference in the optimal number of clusters between the two embedding models, but qualitatively I thought embeddings-gte-base embedding clustering performed better and made key distinctions between certain types of user queries.
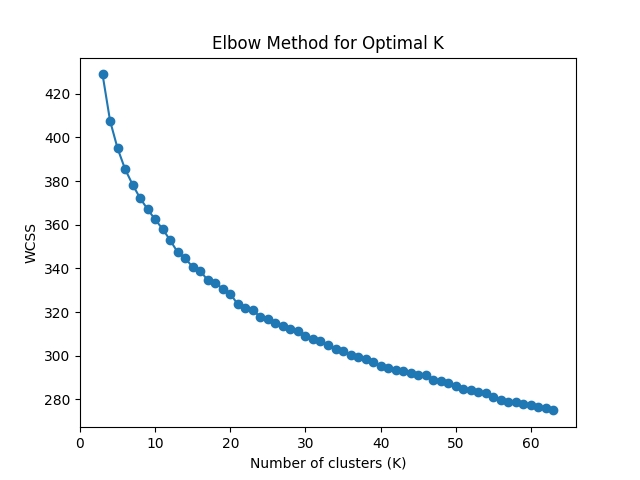
I also ran a GPT prompt across all the AI responses asking it to flag places where the chatbot failed to find the right documents, didn’t find an exact match to the subject, or gave a hesitant or unsure or not enough information-type answer. These steps produced the following clusters and results:
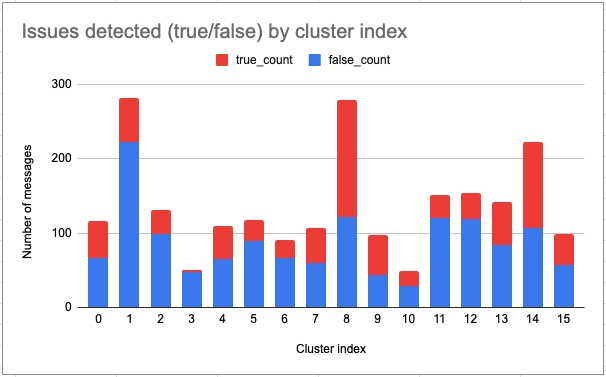
Looking at the contents of the clusters, I labeled them as the following:
Cluster Description
0 Asking for what eating club events are happening
1 Asking for official information about Princeton (e.g. programs)
2 What upcoming club meetings are happening soon? (sample query)
3 How can I get involved in entrepreneurship at Princeton? (sample query)
4 Asking about upcoming events of specific types (sport, dance, etc.)
5 Asking for events that offer free food or drinks
6 Asking for details about specific course numbers
7 General questions about certain eating clubs and bicker
8 Queries referencing a specific name (mostly searching their own name)
9 Tips for success in classes, comparing two classes, listing out classes
10 Queries that reference the word "Tiger" (e.g. Tiger Investments)
11 Asking for info/opinion about food, either eating club, dhall, or outside
12 More questions about clubs (e.g. name me some clubs, what club meetings)
13 Asking for class details (e.g. documents) and dates (academic, class specific)
14 Various questions referencing specific locations, events, groups, and people
15 Asking about difficulty of specific classes
Since the AI assistant invokes different tools to answer the queries, I was curious to see the performance grouped by cluster and tool usage. Running this through Pandas and Seaborn gave the following plot:
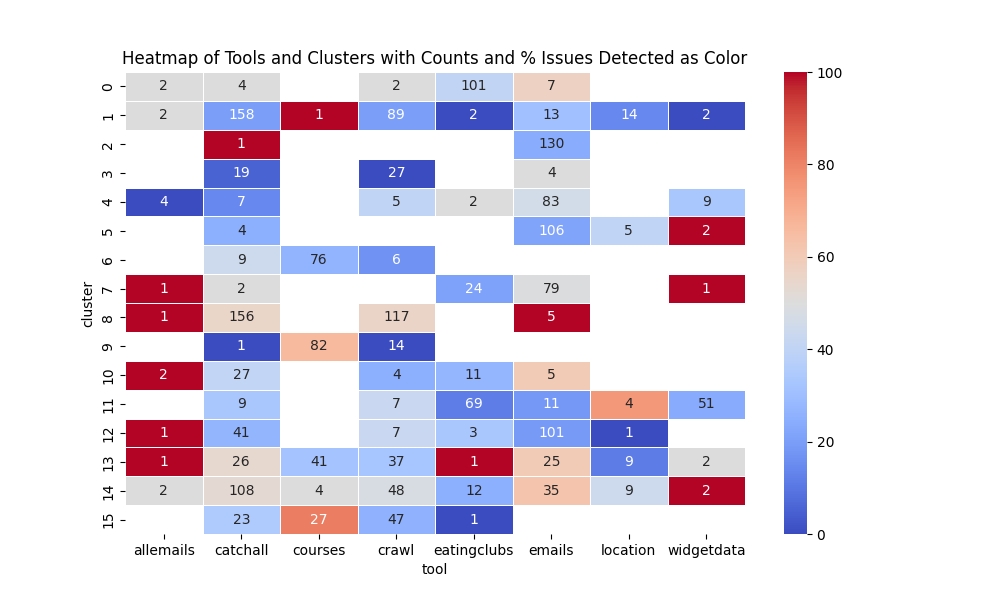
Blue squares: low % of issues. Red squares: high % of issues. Annotated with query counts.
The heatmap confirms that the cluster descriptions I came up with are accurate. We see that each cluster has roughly 1-2 tools that it tends to route to. For instance, cluster 5 (queries looking for events with free food or drinks) routes almost exclusively to the email search tool, which is the tool that best reflects current campus events. We also see the specific areas where there needs to be improvement. For instance, cluster 9 most often routes to the courses tool, but issues arise with responses more than 50% of the time. Cluster 14 seems to have a very wide spread of tool usage, which may indicate that we’re missing an appropriate tool to answer those types of questions.
Cluster 8, which is almost exclusively students searching for their own name, has the highest issue rate. While the chatbot isn’t supposed to support those types of queries beyond the instances where a student’s name was mentioned on official channels, this seems like a promising avenue for virality (or at least a good first impression of the AI).
Overall, I think the results look pretty good for a first pass. This analysis has identified the specific places where we need to improve, and now we can better target our development efforts.
Mobile app
Getting people to use this chatbot means finding the right form factor. Right now, all the conversations were logged through the web interface, accessed from a computer or a phone web browser. However, to get more students to consistently use the chatbot and have it available at the exact moment they need it, we think its a good idea to make a mobile app. Thankfully, Capacitor.js makes this really easy by porting our web code to iOS with just a couple commands. We’re hoping to make quick progress in this direction and get something out.
Perplexity comparison
The day the Perplexity focus mode came out, a lot of my friends messaged me asking me to look at it. While I was surprised at how well it performed, it had very obvious shortcomings across key areas. Here are a couple comparisons I was able to make while testing it out:
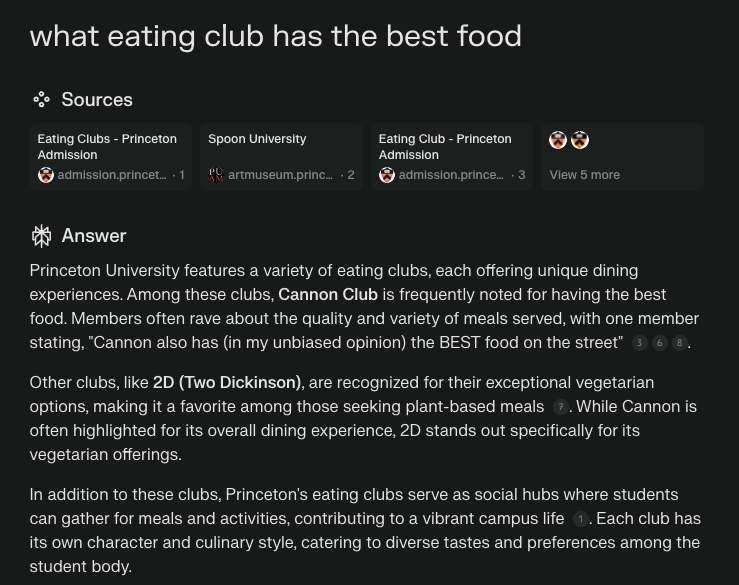
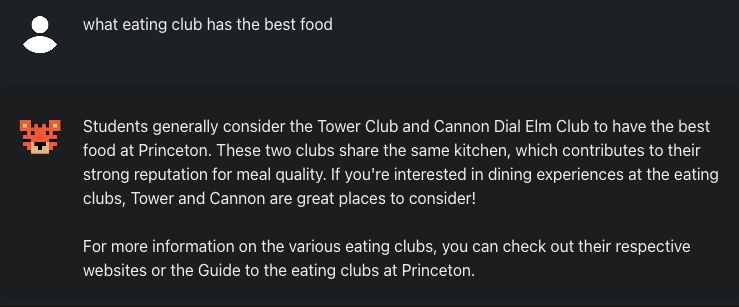
Perplexity makes a classic mistake where it can’t tell the difference between an eating club and a normal club / co-op. For reference, 2D is a co-op, not an eating club. This delination is hard to learn for an LLM, especially on messy public data. When you feed context to a model that appears plausible but unrelated, it can’t reason like a human and understand that 2D is a different concept from the query subject.
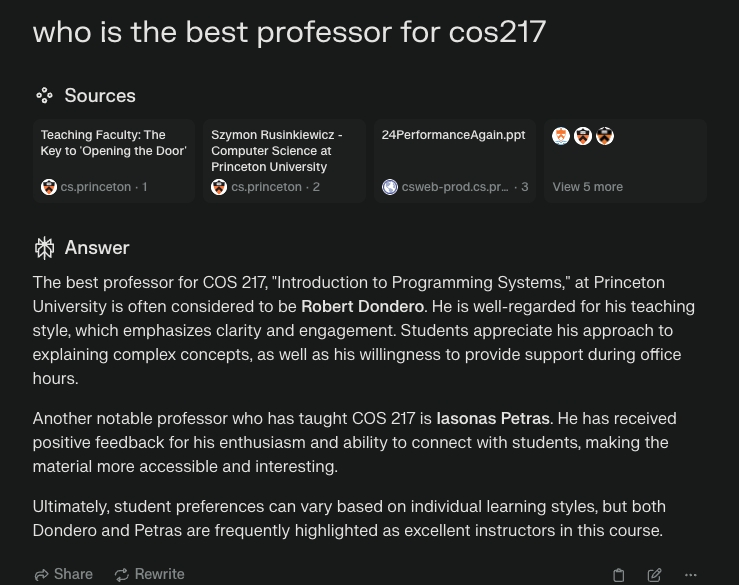

Here, Perplexity simply doesn’t know the answer to this question. It gives some incorrect response based on some public data. On the other hand, our chatbot is integrated into Princeton’s private data ecosystem where we are able to access detailed course information and student reviews. This integration is a distinct advantage that our system (or any private search engine) will have over Perplexity.
Similar behavior happens when you ask Perplexity for upcoming events. While it can answer about some events that are publicly advertised, it really doesn’t know about anything that is going on. If we look at our cluster heatmap, we see that at least 1/3 student queries require accessing real-time event information.
It seems like Perplexity is going to have a hard time breaking into niches like this. Even with all the publicly available data, the LLM cannot understand or reason about concepts correctly. It’s misled severely by extraneous context that any human would have no problem filtering out. For my chatbot, I made specific design decisions to avoid ambiguities in context for cases like eating clubs, but that required having domain knowledge of the Princeton ecosystem. However, I can imagine a future where an AI could reason about this correctly. The eating club distinction is something that any human would understand within 5 minutes of reading. But current LLM designs aren’t there yet.
One area where I was surprised by Perplexity’s performance was their knowledge of some informal facts about campus life. When building my chatbot, I thought that crawling websites outside the Princeton domain (and some exceptions) would be too risky. For instance, there is a ton of unfairly negative press around eating clubs online, which I didn’t want to reflect in the AI responses. Perplexity seems to handle that quite well and still extract key insights from sources that might be biased or anecdotal.
Regarding private data, there is no competition unless Perplexity develops partnerships and builds integrations. They are starting to do that with their Perplexity for Internal Search and various partnerships. For the student use case, I don’t see how it will become useful anytime soon, and I think that’s the case for most places where you could build a private search solution.
I’m interested in seeing where Perplexity goes next. I really wonder how much advantage an AI company can get while operating on public data only. SearchGPT is coming out soon from OpenAI, which would be a strong competitor given how many regular people use ChatGPT already. It might come down to the scenario that many are predicting with LLMs in general where they become commodities, all trained on the same dataset. I do think building a system that can actually read and learn concepts is within the realm of possibility and would elevate this type of search to the next level.